Optimización SQL en Oracle. Últimos retoques.
¡Por fin!
El libro «Optimización SQL en Oracle» está terminado.
En cuanto finalice el diseño de la portada y la contraportada (si los de Amazon no ponen impedimento) ya estará disponible para comprar tanto en amazon.com como en amazon.eu.
El libro ha contado con dos revisores técnicos de peso, que le han sacado punta a todo y han sentado a debate tanto los ejemplos, imágenes y conceptos expuestos, como la filosofía de trabajo del libro. Son Arturo Gutierrez y Jetro Marco. Gracias a ellos el libro ha pasado de unas 316 páginas a las más de 420 actuales.
El índice finalmente ha quedado así:
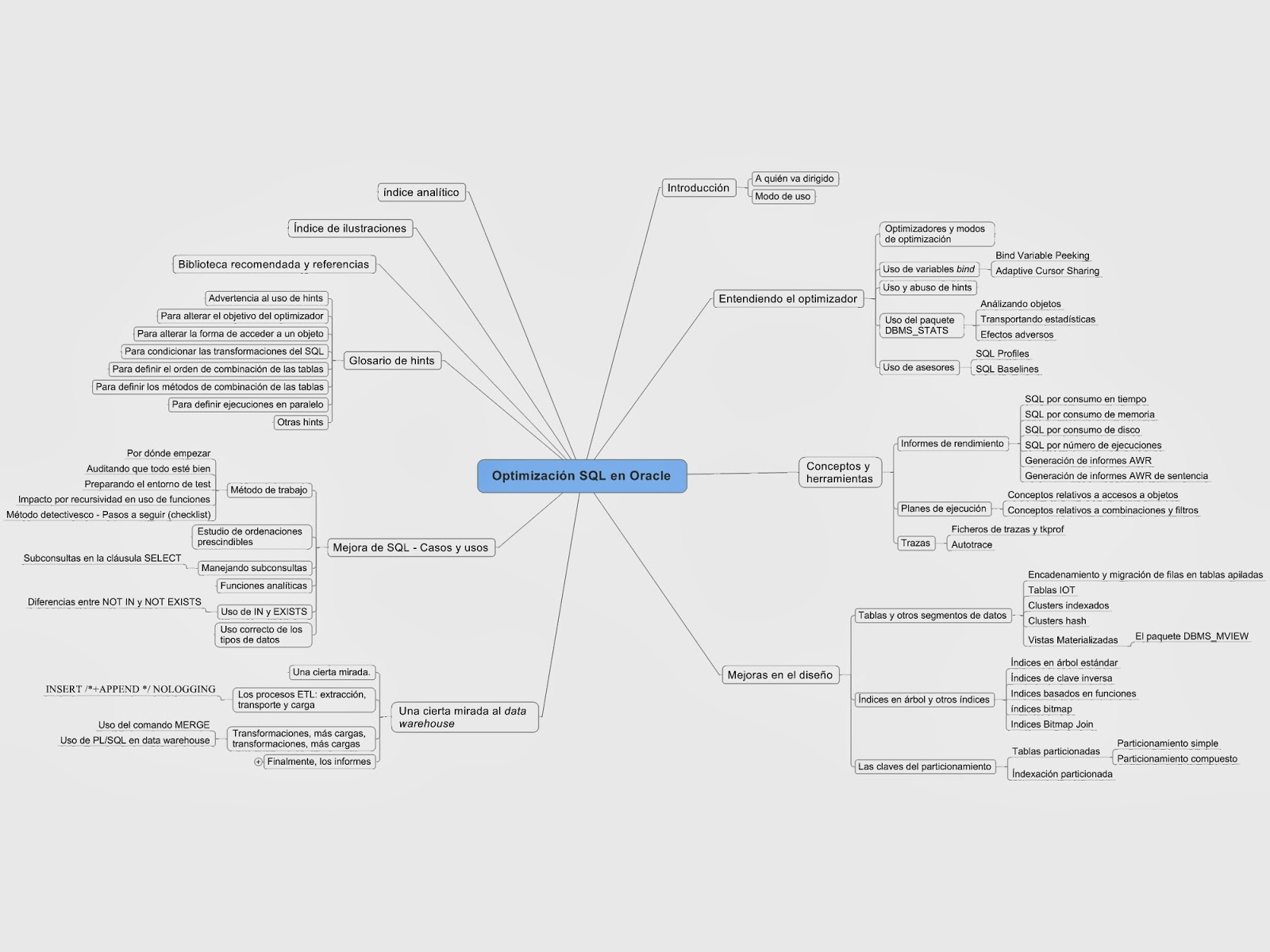
Al final abordamos todo desde las tripas, tanto el tratamiento de las bind variables como el funcionamiento del Bind Variable Peeking, el Adaptive Cursor Sharing, el como SQL Profiles, SQL Baselines, reescritura de vistas materializadas, el paralelismo, particionamiento, así como trazas y planes de ejecución de todo.
El libro está lleno de técnicas, herramientas, base de conocimiento y nuestro aporte profesional sobre cómo optimizar cualquier SQL que de un mal rendimiento. Nos metemos a contar qué pasa en particular con los entornos data warehouse (¿Se puede ejecutar PL/SQL masivo en un entorno data warehouse? … pues hay un capítulo que trata de cómo hacerlo a un rendimiento brutal!), desmontar mitos, descubrir la realizad subyacente de trucos como lanzar INSERTS con APPEND y cosas así. ¿Por qué Oracle dice que seguirá un plan de ejecución y luego decide utilizar otro? ¿cómo lidiar con todo esto sin volvernos locos????
Hemos destripado todas las hints, poniéndolas a prueba. Hemos buscado ejemplos de SQL ineficiente y de múltiples ejecuciones de un mismo código para rizar el rizo y comprender qué sucede en el CBO, cómo se estima la cardinalidad de las operaciones, por qué (a veces) Oracle se equivoca y por qué a veces somos nosotros los que no entendemos al motor.
Además, la bbdd está disponible para descargar gratuitamente aquí, y el SQL del libro (próximamente)!