En breve estará a la venta mi libro «Optimización SQL en Oracle».
Durante los últimos dos años he estado escribiendo este libro que resume, a mi modo de ver, todo lo que un administrador o programador debería conocer para optimizar código SQL.
En él describo cómo funciona el optimizador y cómo se comporta el servidor para escoger los mejores planes de ejecución, los aspectos a considerar para crear tablas de diferentes tipos (tablas IOT, clusters, tablas particionadas, etc.) y lo mismo relativo a los índices. Herramientas para optimizar SQL, desde asesores a las herramientas «manuales» como explain plan, tkprof, autotrace, generación de trazas, análisis de AWR, etc.
Además, también dedico un apartado a los entornos datawarehouse, a optimización SQL de código ineficiente con casos prácticos resueltos, y un glosario completo de hints con ejemplos de su uso y «maluso», y sus consecuencias para el rendimiento.
Este libro responde preguntas y cuestiones habituales como el motivo por qué no siempre es eficiente acceder a las tablas usando índices, escenarios ineficientes, usos incorrectos de tipos de datos y sus consecuencias en la optimización, uso correcto del paralelismo, el particionamiento, las vistas materializadas, jerarquías, dimensiones, consecuencias de usar NOLOGGING, como tratar subconsultas, uso de IN y EXISTS, DISTINCT, ordenaciones, etc.
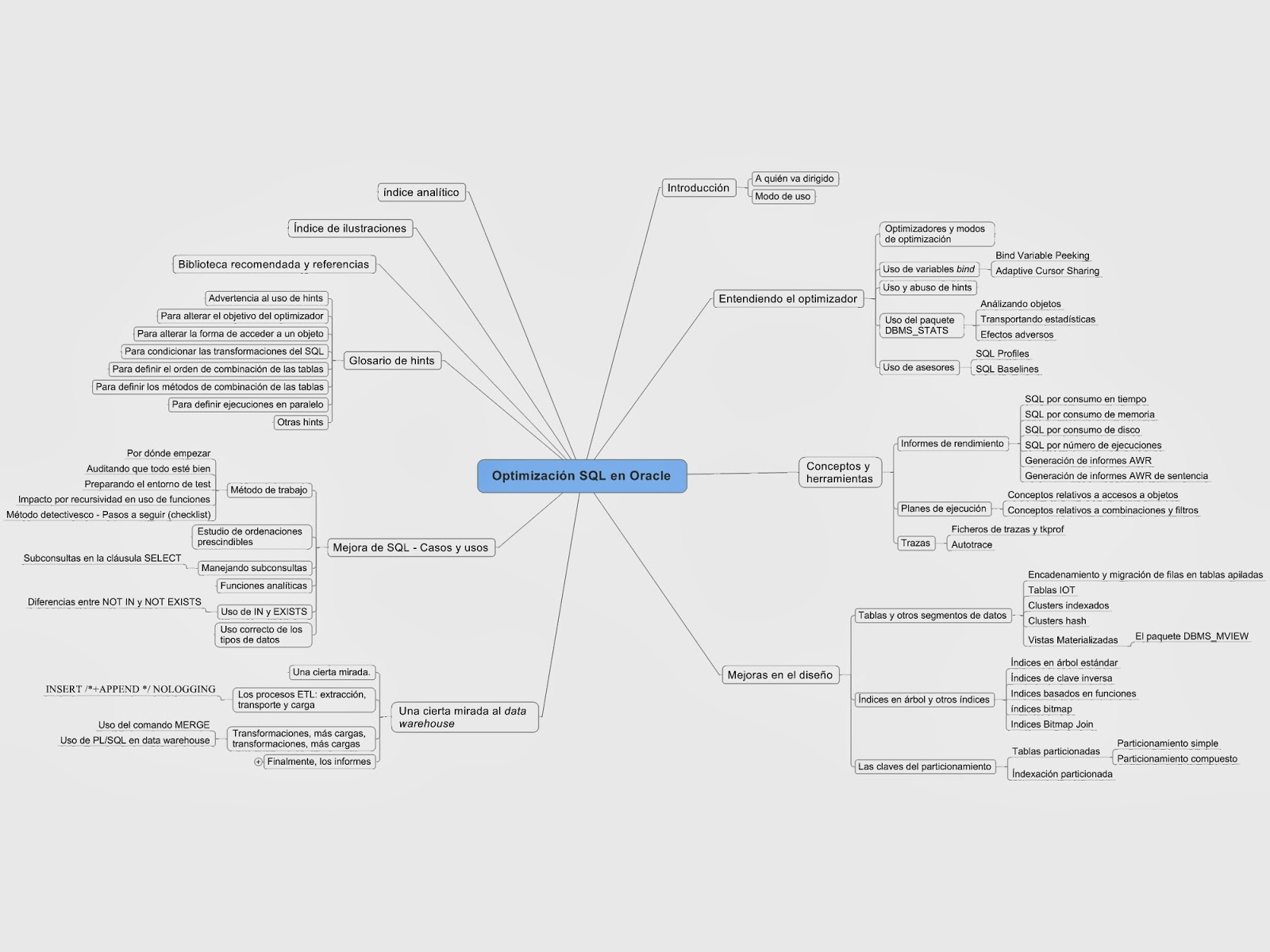
El esquema del libro es el siguiente:
Por el momento está en fase BETA, pendiente de revisión técnica. Para esta revisión cuento con dos administradores de los más fuertes de España, y vamos a asegurarnos que en las más de 300 páginas no se nos escapa un error.
Me gustaría decir, como los de Valve, «When it’s done, it’s done» como fecha de publicación, pero espero que en cosa de un par de meses pueda estar disponible a la venta.
Estoy contento porque se trata del primer libro en español que trata exclusivamente de optimización SQL y todo su universo. Muchos libros (principalmente en inglés) tratan de aspectos del rendimiento, sobre todo del motor (memoria, procesos) o se centran exclusivamente en administración o programación, pero éste es el primer libro que conozco absolutamente específico, en español, con ejemplos en español, tablas con nombres en cristiano (vuelos, reservas, etc.), sin ser una traducción de una obra en inglés o un copia/pega de partes de la documentación de Oracle.
Yo estoy satisfecho del resultado, y espero que pueda ser de utilidad. Estoy seguro de que incluso los usuarios más avanzados se sorprenderán aprendiendo cosas nuevas, o redefiniendo conceptos, o encontrando una forma práctica y accesible de resumir las funcionalidades y componentes que afectan a la eficiencia del servidor de base de datos.
Os dejo unas imágenes del libro, en fase BETA, listo para revisarlo y corregirlo antes de sacarlo a la luz.